
Config Wars - Chapter 5: What to Choose?

Welcome to “Choosing a Schema for Your Robotics Stack!” This series is designed to help scaling robotics teams understand why schemas are useful for their configuration management and navigate which schema is best suited for their stack.
In this blog, we’ll wrap our deep dive into schema languages. We’ll compare JSON Schema, CUE, and Protobuf head-to-head, share some honorable mentions for schema languages, and finally, discuss which schema language Miru chose to support for our config management system.
Intro: A Quick Refresher
Throughout this series, we’ve explored the importance of configuration management in robotics and why schemas are useful in helping scale these config systems:
Configurations (Configs) are an important part of the infrastructure equation when scaling a fleet of robots. Configs are a set of parameters, injected at runtime, that influence our robot’s behavior. They help us adapt to different hardware versions, operating environments, and use cases without needing to modify application code. Instead, we can dynamically swap configs in and out, giving our system modularity and scalability.
The ankle biter that scaling robotics teams face with configs is that they don’t use a schema. They usually use YAML or JSON files, which are error-prone and manual; it’s easy for misconfigurations to be deployed to the robot, causing the application to crash. They also lack any tooling that helps scaffold your config system as you scale.
In this series, we introduced schema languages as the best way to scale and harden your config system. Schema languages provide a structure for configs: they define valid values, set constraints, and support typing. They also have a variety of validation and code generation tools that make it easy to perform DevOps functions around your configs.
We spent this series carefully examining JSON Schema, CUE, and Protocol Buffers (Protobuf).
JSON Schema
JSON Schema is a standard for describing and validating the structure of JSON data. Think of it as a contract that defines what a valid JSON object looks like, specifying types, required fields, constraints, and structure.
JSON Schema is one of the most widely adopted schema languages today.
It boasts a multitude of strengths, including a mature ecosystem, robust third-party validation libraries, and comprehensive tooling support across various languages.
It lacks some functionality regarding overrides, templating, and logic. Teams usually pair it with an external templating engine, such as Jsonnet or Jinja, to fill these gaps.
If your team is already using JSON or YAML and wants strong validation and wide compatibility, JSON Schema is a solid choice.
CUE
CUE, which is short for “Configure, Unify, Execute” was developed at Google by Marcel van Lohuizen, one of the original creators of Go. The original motivation stemmed from Google's internal struggles in managing complex, large-scale configurations for infrastructure and applications. JSON and YAML were too weak for expressing constraints, logic, or composition, so CUE set out to solve that.
It combines validation, logic, and composition into a single language, making it especially useful for teams managing complex and dynamic configs.
CUE’s strengths come from its logic and computation. You can write conditionals, compute derived values, and merge overrides natively. In terms of logic and expressiveness, CUE offers more out of the box than any other schema language we’ve evaluated.
The downside is that CUE has limited language support outside of Go. While the ecosystem is growing rapidly, this issue will persist in the short to medium term. Teams using CUE alongside other languages will need to translate CUE into JSON Schema to unlock code generation.
If you’re looking for a config language that combines logic, inheritance, and validation in one place, CUE is an option worth exploring
Protocol Buffers (Protobuf)
Protobuf was created by Google in the early 2000s. The team needed a compact, fast, and language-agnostic way to serialize structured data. The performance offered by XML and JSON wasn’t cutting it, both in terms of size and speed.
It offers best-in-class code generation and excellent support for static typing and schema evolution. With plugins like protovalidate, you can also add runtime validation to match the flexibility of other schema languages.
The glaring downside with Protobuf is that it wasn’t designed for configuration. It lacks native support for overrides, templating, and logic. You’ll need to handle inheritance and composability manually or with external tooling.
If you need compact, versioned, type-safe configs that compile down to a binary and integrate with firmware or message-passing systems, Protobuf is a strong choice.
Before we get to the grand finale (the part where we compare these three schemas and everyone rides into the sunset), it’s worth mentioning a few tools that are worth knowing about, but just fell short of deserving a deep dive
Honorable Mentions
Pkl:
Pkl (pronounced “Pickle”) is a modern config language developed by Apple. It combines JSON-like syntax with a real type system, a modular system, and even object-oriented features like inheritance and visibility modifiers.
It stands out for its strong support for reusability and testing. You can write unit tests for your config and create base classes for components. The ergonomics feel like configs as code.
It has positioned itself as a ‘configuration DSL’, with a promising direction. The problem is that it’s still young. The tooling ecosystem is limited, especially for robotics-adjacent languages.
Dhall:
Dhall is a functional programming language specifically designed for configs. It’s strongly typed and deterministic; you can write configs like code with imports, functions, types, and guarantees. However, it isn’t Turing-complete.
One of Dhall’s core promises is safe refactoring. You can define types once, import them across files, and be sure that nothing breaks when you change things upstream. It also supports normalization and diffing, which is great for reviewing config changes in CI.
Unfortunately, Dhall has a steep learning curve. Its syntax is unique: lambdas look like λ(x : Text) → x ++ "!", and even simple expressions can feel complex. For most teams, the tradeoff to learn a foreign syntax isn’t worth it. It's a nail in the coffin that, like Pkl, it lacks codegen support for both Rust and C++.
Jsonnet + Jinja:
We’ve referenced these two a few times throughout the blog. They’re powerful, but are only an honorable mention because they aren’t a schema language. They’re templating engines.
They’re widely used across robotics teams to generate structured configs.
Jsonnet is a data templating language (surprise, surprise, created by Google!) that lets you write JSON with variables, conditionals, and functions. As we showed previously, you can write your config in Jsonnet and then validate it against JSON schema.
Jinja is a string-based templating engine for Python. It’s less structured than Jsonnet in that you’re just generating text, but it’s familiar and easy to use in Python. You can loop over variables and render JSON/YAML.
These tools are great for creating overrides or conditional logic, but by themselves, aren’t robust enough. You still want validation, type checking, and codegen offered by schema languages.
Use them together!
Putting it All Together:
We’ve now seen how JSON Schema, CUE, and Protobuf handle validation, codegen, overrides, and their associated DevX. Let’s look at how they stack up head-to-head.
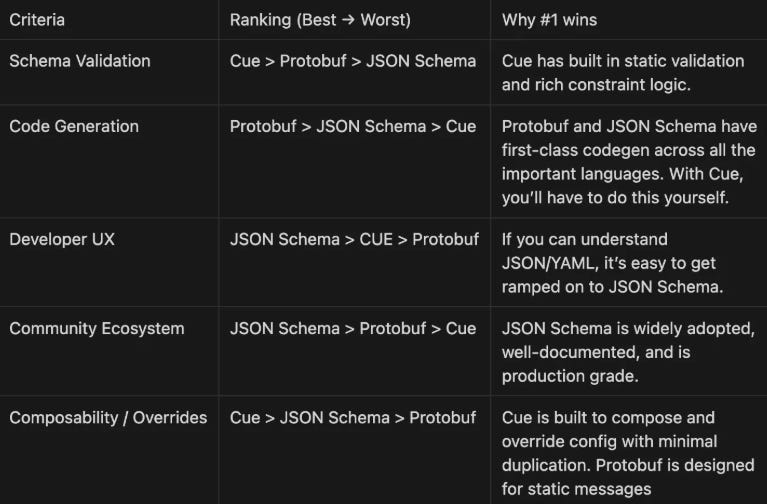
Schema Validation
CUE is the only schema format that has native validation and programmable logic constraints. With the other two, you’ll have to use an external validation method.
This isn’t inherently bad, but it’s much easier when you can validate configs as code using CUE.
Code Generation
It’s a close call here between Protobuf and JSON Schema. Protobuf wins because its codegen tooling is more robust. C++, Python, and Rust are all supported out of the box. Its outputs are also better; JSON Schema generates data models, which are useful but not as powerful as the serialization and deserialization, as well as getters and setters, that Protobuf generates for you.
Developer UX
While CUE has the most expressive syntax, JSON Schema may have the best UX. It’s familiar, supported by every major editor, and integrates easily into workflows already built around YAML or JSON. Protobuf is more rigid and requires a build step, and CUE’s syntax can be tough to onboard.
Community Ecosystem
JSON Schema has the richest community ecosystem. You can find supporting libraries across every language you can think of. It’s not just the codegen and validation use cases that we’ve mentioned. If you do some more digging, you’ll find some more esoteric examples like this reverse gen, NixOS to JSON Schema converter 🙂
Composability / Overrides
Again, CUE wins here because of its native support. You can override layered config and merge config fragments using CUE’s unification model. CUE ensures that overrides don’t accidentally violate constraints, and conflicting fields will fail to unify unless they’re compatible.
When to Use What:
CUE
If you want built-in validation and native override logic, CUE is your best choice. Because CUE is self-encapsulating, you won’t have to use any third-party libraries. However, its codegen is weak for robotics-specific languages. This means you’ll be on your own to build this tooling.
Protobuf
If you’re already using Protobuf for telemetry or message parsing, it makes sense to use it for your config system as well. It has robust schema enforcement, versioning, and codegen.
JSON Schema
If you’re already familiar with YAML/JSON, JSON Schema is a good option. It has well-supported validation and tooling integration, and boasts a strong community of maintainers.
Wrapping it Up:
In this series, we walked through configuration schemas, why they are important for scaling robotics teams, and introduced you to a few schema languages (along with some decision criteria).
What language do we prefer for Miru’s config management infrastructure? Well, all of them. All the options that we’ve discussed are perfectly reasonable, and we plan to support them.
Resources are limited, though, so we had to choose one to focus on initially. We decided on JSON Schema. Here’s why:
It was the easiest for teams to adopt. If they were using schema-less JSON or YAML, the migration wasn’t too painful.
It has a large, mature community.
It supports codegen for all the languages we care about (C++, Rust, and Python)
It has a litany of third-party tools from validators to templating engines and more.
For our Protobuf and CUE lovers, worry not, we’ll work quickly to support them!
In the meantime, give JSON Schema + Miru a whirl to see how the combination makes scaling config management painless.
Happy building, and feel free to reach out with any questions!