
Choosing a Schema Language for Your Robotics Stack


Intro
You’ve done it! You’ve officially gone from 0 to 1. You started with a crazy idea for a robot that could automate a task for a customer, and after countless iterations, you built a prototype. After more testing and tuning, it worked, not just in the lab, but in the field. You shipped it to your first customers, and they love it.
Now, you’ve set your ambitions higher. Instead of just a few robots in production, you want 10s, 50s, or 100s across customer sites around the world. It’s time to scale.
To scale, the entire team will have their hands full.
The hardware team will need to finalize the BOM and establish QA for a growing fleet.
The ML team needs to generalize their models across new customers and environments.
And the software infra team? They’ll be tackling today’s topic: configurations!
At the scale of just a few robots, most teams are using vanilla JSON/YAML. They’re iterating very quickly, constantly experimenting and manually tuning parameters. The robot fleet and codebase are small enough such that it’s tractable for SWEs to remember which configs do what, why specific fields have been modified, and manage the fleet’s configuration. Usually, along with some light version control, the fleet’s configuration is in a manageable state.
However, to support your scaling efforts, you’ll want to move to a configuration system defined by a schema language.
A schema defines the structure of your configuration. It lets you validate configurations before they are deployed, catch mistakes early, and prevent multiple teammates from stepping on each other’s toes. It also sets you up for versioning, diffing, CI/CD, and code generation, workflows that you’ll need in production.
As I’ve seen, for teams comprised of engineers from the world of embedded/robotics, it’s difficult to choose the correct schema language. Historically, schema languages have been used in cloud software, either for SaaS applications or large-scale backend infrastructure. This means our friends in robotics don’t have much first-hand experience.
In this blog, we’ll give you all the information you need to choose the right schema for your production fleet. We’ll walk through what a schema language is, why they’re useful, our main criteria when choosing a schema, and finally, a few options for popular schemas in robotics.
Let’s dive in!
What Are Schema Languages, and Why Do They Matter?
Schema languages define the structure, types, and rules your configuration data must follow. In practice, they describe things like:
What fields are required
What types each field should be
What values are allowed (enums, ranges, patterns)
Depending on the language, what defaults or logic apply
Schema Example:
navigation: {
max_speed: float & >=0 & <=5 // meters per second
min_speed: float & >=0 & < max_speed
safety_margin: float | *0.2 // default to 0.2 meters
mode: "indoor" | "outdoor" // enum
localization: {
method: "ekf" | "fastslam"
enabled: bool | *true
}
}
In this example of a navigation module config, we can see how a schema is useful. It constrains speed values, sets defaults, uses enums for mode, and nests a localization block with its own rules.
This will be important as we scale and are changing these values for each robot. No fat fingering that makes it to production!
The most useful schema languages also solve scaling problems by making configs easier to write, validate, version, and generate code from. They can:
Catch errors early with static validation
Auto-generate boilerplate code or documentation
Compose and override configs across environments
Enable runtime introspection
Choosing a Schema Language
Not all schema languages were built for the same purpose. Some came from web APIs, others from serialization, and others were designed with configs in mind. Each comes with tradeoffs.
When picking one, these are the dimensions we see robotics teams care about most:
Core Dimensions:
Validation Model:
When does the schema catch errors? Runtime? Compile time?
Does it support required fields, type checks, value constraints, etc.?
Code Generation:
Can you generate code from your schema in languages that we (robotics teams) care about (structs or classes in C++, Python, or Rust)?
Composability / Overrides:
Can you override or extend configs cleanly across environments?
How easy are these overrides to create? What kind of logic do we write?
How powerful are these overrides? What level of granularity can we unlock?
Templating / Logic / Computation:
Can you express conditional logic, like if statements
Can you use variables, functions, or computed values in your config?
Is the language Turing-complete? If so, what are the potential side effects?
Self-Documentation / Readability:
Does the schema support built-in descriptions and field-level metadata?
Can a new engineer understand the config by reading it? Is it easy to edit and debug?
Can it double as internal documentation?
Will your team hate you for choosing it?
Tooling Ecosystem:
How production-grade and well-maintained are its tools?
Is there an official
validatelibrary that works well?Can you integrate schema validation into your CI/CD pipeline?
These are some nice-to-haves worth mentioning:
Bonus Dimensions:
Change Safety / Drift Detection:
Can you detect when a config change happens and perform taint tracking?
Can you diff between config versions?
Declarative vs Imperative Semantics:
Is the language declarative (describe what the config should be) or imperative (describe how to compute it)?
How much complexity is acceptable for your config system?
Schema vs Instance:
Does the schema live in a separate file from the config instance?
Or is it all blended into a single file (logic, constraints, and data)?
Now that we’ve highlighted our criteria, let’s deep dive into a few schema languages!
Deep Dive
JSON Schema
History / Motivation:
JSON Schema is a standard for describing and validating the structure of JSON data. It’s like a contract that defines what a valid JSON object looks like, specifying types, required fields, constraints, and structure.
Origins:
JSON Schema was introduced in 2010. At this time, JSON was rapidly becoming the standard format for APIs. However, it had a growing problem. For all its benefits, there was no standard way to validate its structure.
JSON Schema filled this gap and gave JSON a similar schema definition to XML’s XSD.
Initial Use Case:
The first major use case was API request and response validation. JSON Schema lets developers validate incoming payloads. It was soon adopted in OpenAPI (at the time called Swagger) and became the backbone for API schemas and documentation.
Usage in Practice:
JSON Schema wasn’t originally designed for configs, but since it’s become the default option for validating JSON, it has begun to pop up in config systems.
Outside of that, here are some places we see JSON Schema in use.
OpenAPI: Uses JSON Schema to describe request and response payloads. If you’ve written an OpenAPI spec, you’ve used JSON Schema
Docker Compose: Uses embedded schemas to validate service definitions and flag misconfigured keys.
AsyncAPI: Builds on JSON Schema to define the structure of events and messages.
Kubernetes Custom Resource Definitions (CRDs): Kubes uses JSON Schema to validate resource specs and reject invalid YAMLs before it applies the resource to the cluster.
Community & Ecosystem:
JSON Schema has one of the most active and mature ecosystems of any schema format. It’s maintained by the JSON Schema organization, with regular drafts and updates. 2020-12 is the current draft.
Github Activity:
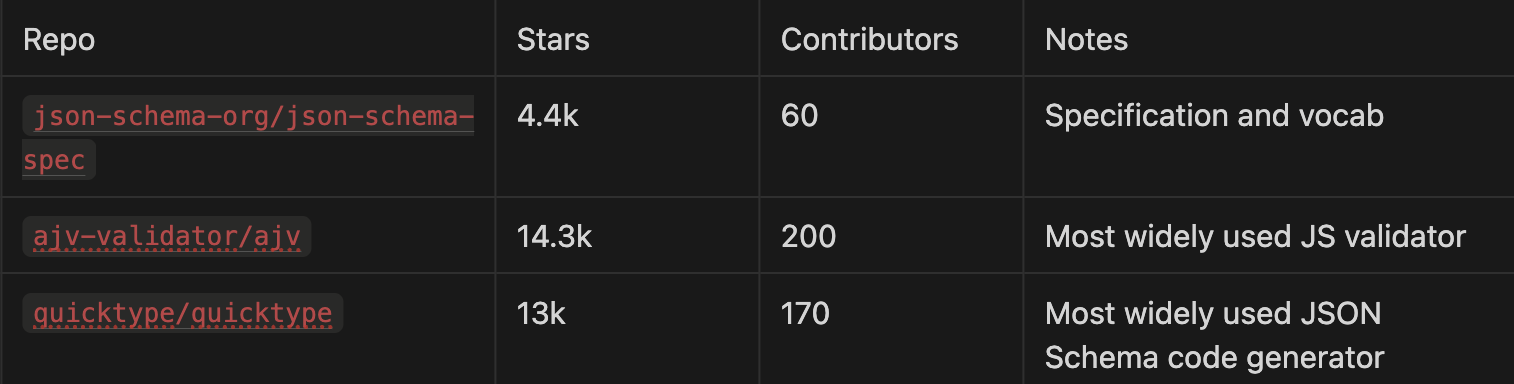
Tooling:
The community and tooling around JSON Schema is huge. You’ll find production-grade libraries for nearly every language:
JavaScript:
ajvPython:
jsonschemaGo:
gojsonschemaRust:
jsonschema,schemafyC++:
json-schema-validator
It also supports code generation with tools like:
quicktype– generates idiomatic types for many languagesdatamodel-code-generator– for Python, generated via Pydanticschemars– for Rust via Serde
Finally, it has editor support for VS Code, IntelliJ, etc. to power autocompletion, validation, and inline documentation.
Something to be careful about: JSON Schema doesn’t have an official validator or CLI. This means you have to use a third-party library. Please make sure the library is active and well-maintained before committing to it in production!
Another consideration, YAML is considered a second-class citizen in JSON Schema. While you can apply schemas to YAML (we often do internally, as you see with the examples we share), the experience is less robust than using JSON.
Feature Evaluation
Validation:
JSON Schema was initially built for validation, so it’s natural that it is strong here.
It gives you a declarative way to define rules like:
Required fields
Type checks (
string,number,boolean, etc.)Enum constraints (
statusmust be one of["idle", "active", "error"])Min/max for numbers, length limits for arrays
Regex patterns for strings
Nesting for objects-of-objects
Validation happens at runtime via a separate library like ajv or json-schema-validator . This means that there are no compile-time guarantees. You’ll have to validate before loading the config in your app.
It’s strong for config validation for predictable, bounded checks; however, it lacks the expressive power for computed defaults or logic. You won’t be able to do, “if motor_type is servo, then gear_ratio must be set.”
Code Generation:
JSON Schema makes it easy to generate typed models in your language of choice from your schema.
You can generate:
Python classes with
datamodel-code-generator: A codegen tool that converts JSON Schema, OpenAPI, or raw JSON samples into Pydantic model classes.
Rust structs with
schemafy: Takes a JSON Schema and generates Rust types that implement Serde traits. Great when you want strongly typed config parsing from schema definitions.
C++ classes with
quicktype: generates idiomatic C++ classes withnlohmann::jsonintegration
Here’s an example of going from JSON Schema to a Python class using
datamodel-code-generator :
JSON Schema:
{
"type": "object",
"properties": {
"robot_id": { "type": "string" },
"enabled": { "type": "boolean" },
"max_velocity": { "type": "number", "minimum": 0 },
"sensors": {
"type": "array",
"items": { "type": "string" }
}
},
"required": ["robot_id", "enabled"]
}Here’s the generated Python class:
from typing import List, Optional
from pydantic import BaseModel, Field
class RobotConfig(BaseModel):
robot_id: str
enabled: bool
max_velocity: Optional[float] = Field(default=None, ge=0)
sensors: List[str] = Field(default_factory=list)
This model:
Enforces types and constraints at runtime
Sets the minimum on
max_velocityDefaults
sensorsto an empty list if not provided
Composability / Overrides:
JSON schema doesn’t handle this well, natively. It’s a validation spec, so it was never designed to support overrides or schema extensions.
However, there are some workarounds:
Modular schemas using
$ref: lets you break large schemas into smaller parts and reuse definitions. Note that$refis reference only, so you can’t override or patch fields.Compose constraints from multiple schemas with
allOf,anyOf, oroneOf.Use Jsonnet or Jinja to merge and perform overrides at build time.
To use something like Jsonnet, you’ll need a shared base config plus specific overrides for your robot.
Which will give you a workflow like the following:
# Step 1: Compose or override the config
jsonnet robot_07.jsonnet > robot_07.json
# Step 2: Validate the result
jsonschema --schema base.schema.json robot_07.json
Overall, composability and overrides are clunky with JSON Schema.
Note: Check out Miru to see how we make overrides easy w/ JSON Schema 🙂
Templating / Logic / Computation:
Since JSON Schema is declarative and static, it cannot define conditionals, compute derived fields, or loop through a list to generate nested objects.
Any logic must be handled outside of JSON Schema (using a templating engine like Jsonnet, Jinja, or even Cue).
This limits its usefulness where config values are dependent on each other.
Self-Documentation / Readability:
For JSON and YAML enthusiasts, JSON Schema is a familiar format.
You can embed metadata directly into the schema:
description: explain what a field is and how it’s usedexamples: show valid values or common patternsdefault: suggest a fallback value (not enforced)title: optional short label for fields
Here’s what it looks like:
{
"type": "object",
"properties": {
"kp": {
"type": "number",
"description": "Proportional gain for motor controller (unit: N*m/rad)",
"default": 0.05,
"examples": [0.05, 0.1]
}
}
}This metadata makes it easy for folks to get up to speed when reading the config for the first time.
But for readability, JSON Schema can sometimes be a mixed bag:
For simple schemas: readable and easy to follow.
For large schemas: becomes deeply nested, verbose, and hard to write by hand.
Using
allOf+$ref+if/then/elsecan quickly make the file hard to parse
CUE
History / Motivation:
CUE, which is short for “Configure, Unify, Execute” was developed at Google by Marcel van Lohuizen, one of the original creators of Go. The original motivation came from Google's internal struggles managing complex, large-scale configuration for infrastructure and applications. JSON/YAML were too weak for expressing constraints, logic, or composition, so CUE set out to solve that.
CUE was open-sourced in 2019.
It was meant to replace:
Handwritten configs, which were repetitive and error-prone
External scripts for validation
Inability to reuse and override structured data
Config and code being separate, creating mismatches when keeping them in sync
Instead of building and managing external tools to validate, patch, or generate configs, CUE itself is a fully programmable config engine. This means CUE wholly encapsulates the configuration data, the schema, and the logic (how to derive those config values).
Usage in Practice:
CUE is still niche, but it’s gaining adoption in environments where configs are large, layered, and dynamic.
It’s used by:
Teams at Google
Kubernetes projects that need validation beyond YAML
Broadly, teams where JSON Schema isn’t expressive enough, and logic-based merging is necessary
Community and Ecosystem:
CUE has a small, active core team of maintainers, including the original Go team led by van Lohuizen.
GitHub Activity:

Tooling:
CUE ships with a CLI that helps you validate, format, and export your configs
cue vet: Validate data against constraintscue eval: Merge constraints and output final datacue export: Emit valid JSON/YAMLcue fmt: Formatter, likegofmtfor CUEcue def: Convert JSON/YAML into a base schema
Editor Support:
VS Code extension: First-class support with syntax highlighting, formatting, hover docs, and linting
JetBrains IDEs: Limited community support; no official plugin yet
Code Generation:
CUE is tightly integrated with Go, but struggles with other languages.
If you’re not using Go (which most robotics stacks aren’t) your best bet is to go from CUE → JSON Schema → code generation.
For static languages like Rust, this works well. For dynamic languages, you’ll need CI checks to make sure your code and schema don’t drift.
Feature Evaluation
Validation Model:
CUE uses a constraint-based, structural validation model. Instead of separating types from values, CUE treats both as constraints, so you define them in the same place. In CUE, the schema is the set of constraints your data must satisfy.
Here’s an example:
RobotConfig: {
id: string & !=""
armLength: float & >0.1 & <2.0
payloadKg: int & >= 0 & <= 25
mode: "idle" | "active" | "emergency"
ip: string & =~ "^(?:[0-9]{1,3}\\.){3}[0-9]{1,3}$"
}Each field has an inline constraint to prevent misconfigurations. The & operator lets you intersect multiple constraints.
Here’s an instance that conforms to the schema:
myRobot: RobotConfig & {
id: "arm-001"
armLength: 1.2
payloadKg: 18
mode: "active"
ip: "192.168.1.42"
}When you run cue vet, it checks that all constraints from RobotConfig are satisfied by myRobot.
If we change payloadKg to 100, the instance is now invalid:
myRobot.payloadKg: conflicting values 100 and int & >=0 & <=25:
conflicting values 100 and <=25Code Generation:
CUE has poor codegen. There is no way to natively go from CUE to Python, Rust, or C++.
Here’s how you could work around this by going from CUE JSON Schema.
First, create a .cue file. Here’s our robot.cue example.
This defines a Robot type with:
A required
robot_id(string)A required
enabled(bool)A
max_velocitythat must be ≥ 0A
sensorslist that defaults to an empty array
Robot: {
robot_id: string
enabled: bool
max_velocity: number & >=0
sensors: [...string] | *[]
}Next, export it to JSON Schema using cue export.
cue export robot.cue --out=jsonschemaHere’s the JSON Schema output!
{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"properties": {
"robot_id": { "type": "string" },
"enabled": { "type": "boolean" },
"max_velocity": {
"type": "number",
"minimum": 0
},
"sensors": {
"type": "array",
"items": { "type": "string" },
"default": []
}
},
"required": ["robot_id", "enabled", "max_velocity", "sensors"]
}From the JSON Schema, we can generate our Rust struct.
cargo install schemafy_cli
schemafy robot.schema.json > robot_config.rsHere’s the output:
#[derive(Debug, Serialize, Deserialize)]
pub struct Robot {
pub robot_id: String,
pub enabled: bool,
pub max_velocity: f64,
pub sensors: Vec<String>,
}This works, but it’s not first class. You’re stitching together a few different tools, which can cause some lossy translation. For example, going from CUE to JSON Schema means that you lose some of the CUE constraint logic if JSON Schema does not support it.
Composability / Overrides:
CUE does very well here as it has built composability into its language semantics.
CUE uses a logical conjunction (&) to merge constraints and values. That means you can define reusable schemas, partial defaults, and environment-specific overrides as independent pieces and merge them when needed.
Here’s an example of a base + override:
BaseConfig: {
armLength: 1.2
payloadKg: <= 20
mode: "idle"
}
ProductionOverride: {
mode: "active"
payloadKg: 18
}
robot01: BaseConfig & ProductionOverride
Evaluating robot01 merges the two objects. All constraints are preserved and checked at merge time.
{
"armLength": 1.2,
"payloadKg": 18,
"mode": "active"
}This construct allows you to build layered configs, either merging various components together or creating overrides on a per-robot basis. This makes CUE uniquely good for managing configs at scale!
Templating / Logic / Computation:
CUE supersedes the functionality of a templating engine. It’s a declarative language, so you can write rules, expressions, and constraints that safely compute values based on inputs.
CUE supports:
Arithmetic & expressions (
torque / (payload + 1))Conditional logic (
status: if emergency then "offline" else "ready")List comprehensions (
[for id in robotIDs { id: id, zone: "default" }])Constraint merging (
limit: >10,limit: <=25→limit: >10 & <=25)
CUE is not Turing-complete. It can’t do:
Recursion
Unbounded loops
General-purpose function definitions
Import values at runtime
And that’s by design. It’s expressive enough to compute what you need, but also bounded enough to stay predictable. Sometimes, templating engines like Jsonnet and Jinja can be too powerful. They can introduce infinite loops and runtime failures that deliver a bad config, and therefore crash your application.
Self-Documentation / Readability:
CUE is reasonably self-documented. It has a strong type system, default values, and field declarations. However, compared to JSON Schema, it lacks richer metadata that are nice to haves with a schema language.
Field types are explicit:
name: string
payloadKg: int & >= 0 & <= 25
You can define enums and constraints inline, which makes intent very clear:
mode: "idle" | "active" | "emergency"You can annotate with comments, and they persist through evaluation and formatting:
// Max load the robot can carry in kg
payloadKg: int & >= 0 & <= 25
You can also use cue def or cue export to generate a "flattened" version of the config—useful for introspection or documentation tooling.
That being said, it borrows a lot from Go, so for engineers not familiar with the language, there can be some ramp-up needed.
Protocol Buffers (Protobuf):
History / Motivation:
Protobuf was created by Google in the early 2000s. The team needed a compact, fast, and language-agnostic way to serialize structured data. The performance offered by XML and JSON wasn’t cutting it, both in terms of size and speed.
To keep up with their rocket ship growth, Google needed to efficiently pass structured messages across thousands of internal services written in various languages.
Protobuf was created to solve these problems:
Efficient cross-language serialization. They needed to encode and decode structured data across systems and languages (C++, Java, Python, Go, etc.)
Smaller payload sizes. Protobuf produced a binary format that is smaller and more efficient than XML/JSON
Schema guarantees. Define data schemas with .
protofiles, allowing for type-safe communication between servicesForward/backward compatibility. With services constantly changing, schemas need to safely evolve over time. With Protobuf, you can add, remove, or modify fields with breaking old binaries
Protobuf wasn’t designed for configuration, but over the years, it has been co-opted for this use case in environments where binary formats and strong typing matter. It’s become popular in the world of embedded systems and robotics. That’s great news for us!
Usage in Practice:
Protobuf operates in the infrastructure layer of many distributed systems:
APIs & microservices: Especially with gRPC, which uses Protobuf as its IDL (Interface Definition Language) and serialization format.
Internal service communication: For large-scale systems, Protobuf is often used to reduce payload size and parsing overhead
Embedded systems: Robotics, IoT, etc., anywhere where bandwidth is constrained
Protobuf wasn’t built for configuration, but many teams use .proto files as config schemas, given that they want:
Typed configs and are okay with compiling the schema before runtime
To control the full pipeline (generate configs at build time and deploy as binaries)
Community & Ecosystem:
Protobuf is still led by Google with a mature and production-grade ecosystem. It’s been around for ~15 years, so you’ll find wrappers, plugins, and tooling across every major language.
Github Activity:

Tooling:
IDE Support
VS Code: Extensions for syntax highlighting, autocomplete, and linting.
IntelliJ, GoLand, etc: Built-in
.protosupport for major languages.
CLI Tools
protoc: the compiler that turns.protofiles into codeProtobuf’s CLI,
buf, allows for:Linting
Breaking change detections
Schema Versioning
Dependency management
protovalidate: Adds runtime validation rules. Useful since native Protobuf doesn’t have strong validation.
Feature Evaluation
Validation Model:
Protobuf’s native validation model is minimal. It enforces types but doesn’t support constraints like:
Min/max values
String length
Regex patterns
Cross-field logic
For a real validation, most teams use protovalidate , a buf plugin that lets you define rich constraints directly in your .proto files.
Example with protovalidate
import "buf/validate/validate.proto";
message JointLimits {
string joint_name = 1 [(buf.validate.field).string.min_len = 1];
float min_position = 2;
float max_position = 3 [(buf.validate.field).float.gt = 0];
// Ensure max_position > min_position in application logic
}This snippet ensures:
joint_namecan’t be an empty string.max_positionmust be > 0.You can enforce
max_position > min_positionat runtime via generated validation code.
protovalidate allows you to validate at runtime and unlock most of the validation capability from both JSON Schema and CUE.
Code Generation:
Protobuf has excellent code generation. You define your schema once in a .proto file, and you can easily generate typed, structured code in your language of choice.
Let’s say you have a schema for camera parameters on a robot:
message CameraConfig {
float focal_length = 1;
int32 resolution_width = 2;
int32 resolution_height = 3;
bool auto_exposure = 4;
}You can generate a C++ class using the protoc compiler:
protoc --cpp_out=./generated camera.protoThis generates a camera.pb.h file and a camera.pb.cc file. Here’s a snippet from the former:
class CameraConfig : public ::google::protobuf::Message {
public:
CameraConfig();
virtual ~CameraConfig();
// Getters
float focal_length() const;
int resolution_width() const;
int resolution_height() const;
bool auto_exposure() const;
// Setters
void set_focal_length(float value);
void set_resolution_width(int value);
void set_resolution_height(int value);
void set_auto_exposure(bool value);
// Serialization
bool SerializeToString(std::string* output) const;
bool ParseFromString(const std::string& data);
// ...
};
This gives you:
A single source of truth for shared config structures
Type-safe config access across firmware, host software, and cloud services
Taint tracking. If a field is added or removed, you get a compile-time error in every place it’s used
Protobuf’s codegen is the best in the business.
Composability / Overrides:
Protobuf is not naturally composable in the way that Cue is. It’s more of a strict schema definition than a configuration language.
That said, you can build some modularity using nested messages:
message Resolution {
int32 width = 1;
int32 height = 2;
}
message CameraConfig {
Resolution resolution = 1;
float focal_length = 2;
}This lets you define reusable components and assemble them into larger schemas.
On the override side, oneof can give you some basic functionality.
However, you can’t do hierarchical overrides (base config → fleet config → individual robot config) in the way that you might want to do once you have a fleet of production robots. You also won’t be able to implement any conditional logic.
To get around this, teams either build their override logic into their application code, or use Protobuf strictly for static configs, and use another schema language for more dynamic, runtime configs.
Templating / Logic / Computation:
Protobuf has no support for:
logic, conditionals, or computed fields.
templating, variables, or macros.
expressing constraints like “field A must equal field B + 1”.
Which means that it’s very poor at templating!
The schema is static and must be compiled ahead of time. If you want something more dynamic, you’ll need to couple it with a templating engine like Jinja to generate configs from .proto files.
Self-Documentation / Human Readability:
Protobuf schemas are readable if you know the syntax, but they aren’t designed to double as documentation. Comments are supported, but there’s no built-in support for markdown, structured metadata, or annotations.
// Configuration for the main robot arm camera
message CameraConfig {
// Effective focal length in millimeters
float focal_length = 1;
// Image width in pixels
int32 resolution_width = 2;
// Image height in pixels
int32 resolution_height = 3;
// Whether to enable automatic exposure control
bool auto_exposure = 4;
}
You can describe each field, but the schema can’t explain itself beyond these comments. Of course, once you serialize it into a binary blob, it is certainly not human readable.
Honorable Mentions
These tools/schema languages didn’t make the lineup, but they’re worth knowing. We’ll explore them briefly.
Pkl:
Pkl (short for “Pickle”) is a ~new config language developed by Apple. It combines JSON-like syntax with a real type system, a modular system, and even object-oriented features like inheritance and visibility modifiers.
It stands our for its strong support for reusability and testing. You can write unit tests for your config and create base classes for components. The ergonomics feel like configs as code.
It has positioned itself as a ‘configuration DSL’, with a promising direction. The problem is that it’s still young. The tooling ecosystem is limited, especially for robotics-adjacent languages.
Dhall:
Dhall is a functional programming language specifically designed for configs. It’s strongly typed and deterministic; you can write configs like code with imports, functions, types, and guarantees. However, it isn’t Turing-complete.
One of Dhall’s core promises is safe refactoring. You can define types once, import them across files, and be sure that nothing breaks when you change things upstream. It also supports normalization and diffing, which is great for reviewing config changes in CI.
Unfortunately, Dhall has a steep learning curve. Its syntax is unique: lambdas look like λ(x : Text) → x ++ "!", and even simple expressions can feel complex. For most teams, the tradeoff to learn a foreign syntax isn’t worth it. It's a nail in the coffin that, like Pkl, it lacks codegen support for both Rust and C++.
Jsonnet + Jinja:
We’ve referenced these two a few times throughout the blog. They’re powerful, but are only an honorable mention because they aren’t a schema language. They’re templating engines.
They’re widely used across robotics teams to generate structured configs.
Jsonnet is a data templating language (surprise, surprise, created by Google!) that lets you write JSON with variables, conditionals, and functions. As we showed previously, you can write your config in Jsonnet and then validate it against JSON schema.
Jinja is a string-based templating engine for Python. It’s less structured than Jsonnet in that you’re just generating text, but it’s familiar and easy to use in Python. You can loop over variables and render JSON/YAML.
These tools are great for creating overrides or conditional logic, but by themselves, aren’t robust enough. You still want validation, type checking, and codegen offered by schema languages.
Use them together!
So how should you decide?
Here’s how JSON Schema, CUE, and Protobuf stack up for robotics configs:

When to use what:
CUE
If you want built-in validation and native override logic, CUE is your best choice. Because CUE is self-encapsulating, you won’t have to use any third-party libraries. However, its codegen is weak for robotics-specific languages. This means you’ll be on your own to build this tooling.
Protobuf
If you’re already using Protobuf for telemetry or message-parsing, it makes sense to use it for your config system as well. It has robust schema enforcement, versioning, and codegen.
JSON Schema
If you’re already familiar with YAML/JSON, JSON Schema is a good option. It’s perfectly workable for validation and tooling integration, and has large community support.
Conclusion
In this blog, we walked through configuration schemas, why they are important for scaling robotics teams, and introduced you to a few schema languages (along with some decision criteria).
If you’re curious, for Miru’s config management tool, we started by supporting JSON Schema. Here’s why:
It was the easiest for teams to adopt. If they were using schema-less JSON or YAML the migration wasn’t too painful
It has a large, mature community
It supports codegen for all the languages we care about (C++, Rust, and Python)
It has a litany of third-party tools from validators to templating engines and more
For those who’d prefer to use a different schema language, good news! We’ll be supporting Protobuf and Cue soon.
Thanks again for reading, and feel free to reach out with any questions. Happy building!